Deciphering the Digital Code of Plant Life
In the era of "Big Data," plant research has shifted from single-gene studies to system-wide explorations. Lifeasible provides a comprehensive suite of bioinformatics solutions specifically tailored for plant sciences. We specialize in handling the unique complexities of plant genomes—such as high polyploidy, repetitive sequences, and complex secondary metabolic pathways.
Our platform bridges the gap between raw sequencing reads and biological discovery, offering everything from plant bioinformatics data visualization to the complex modeling plant development and hormonal action. Whether you are exploring evolution or engineering metabolic pathways, our expert bioinformaticians provide the precision and depth required for high-impact publications and industrial breakthroughs.
Gene expression is a tightly regulated process influenced by developmental cues and external stressors. We provide deep-dive analysis into the transcriptional and post-transcriptional landscape of plants.
We offer high-resolution Plant Transcriptome Bioinformatics Analysis that goes beyond simple quantification. Our pipelines identify novel transcripts, alternative start/stop sites, and tissue-specific expression patterns essential for understanding plant development.
Plants employ a sophisticated array of non-coding RNAs as molecular switches. Our platform provides comprehensive Bioinformatics Prediction and Analysis of Plant microRNAs, Bioinformatics Analysis of Plant circRNA, and Bioinformatics Analysis of Plant Pre-mRNA Variable Splicing. These analyses reveal how plants fine-tune their gene expression through post-transcriptional silencing and protein isoform diversity.
The history of land plant colonization is etched into their genomes. We use comparative genomics to trace evolutionary trajectories and genome organization.
We help researchers define species boundaries and evolutionary origins through Phylogenetic and Molecular Evolutionary Analysis of Plants and Plant Genetic Classification Bioinformatics Analysis. These services are fundamental for germplasm characterization and understanding the divergence of crop wild relatives.
Plant genomes are shaped by frequent duplication events and mobile elements. We provide specialized Plant Gene Family Bioinformatics Analysis to track gene expansion and Identification and Bioinformatics Analysis of Plant Transposable Elements to study how "jumping genes" contribute to phenotypic plasticity and genome size variation.


In the post-genomic era, understanding a plant’s phenotype requires more than a single perspective. We focus on the synergistic interactions between different biological layers to decode complex traits.
Our Personalized Multi-Omics Analysis and Joint Analysis of Plant Transcriptomics and Metabolomics services are designed to bridge the gap between genetic potential and chemical reality. By correlating mRNA fluctuations with metabolite flux, we help researchers identify the "bottleneck" genes that control key agronomic traits.
We utilize advanced algorithms for Plant Functional Gene Network Bioinformatics Analysis and Modeling Plant Development and Hormonal Action. These services allow for the prediction of plant growth patterns and stress responses under fluctuating environmental conditions, providing a blueprint for "In Silico" plant breeding.
To ensure that complex multi-dimensional data is accessible and publication-ready, all results are refined through our Plant Bioinformatics Data Visualization service, transforming abstract matrices into intuitive, high-resolution biological maps.
We provide targeted computational support to decode the enzymes and pathways responsible for plant chemical diversity.
Our comprehensive Plant Metabolome Bioinformatics Analysis is integrated with targeted studies on essential pathways, including Bioinformatics Analysis of Plant Starch Synthases, Bioinformatics Analysis of Higher Plant ANS Gene for anthocyanin biosynthesis, and Bioinformatics Analysis of GGPPS Proteins in Medicinal Plant for terpene precursors.
We offer expert Bioinformatics Analysis of Plant Cytochrome P450 and Bioinformatics Analysis of Plant Pleiotropic Drug Resistance Genes to help researchers understand how plants synthesize defensive compounds and transport them across membranes to combat pathogens and pests.
Recognizing the plant as a "holobiont," we explore the microbial communities residing in the phyllosphere and rhizosphere through Bioinformatics Analysis of the Plant Metagenome, uncovering the metabolic synergy between plants and their associated microbes.
![]()
Data Quality Control (QC)
Raw data assessment, trimming, and filtering to ensure high-quality input.
![]()
Mapping & Assembly
Alignment to reference genomes or de novo assembly for non-model species.
![]()
Core Bioinformatics Processing
Execution of specific pipelines (e.g., differential expression, SNP calling, or motif discovery).
![]()
Advanced Functional Annotation
Integrating GO, KEGG, and specialized plant databases for biological context.
![]()
Reporting & Visualization
Delivery of publication-ready figures through our plant bioinformatics data visualization service.
Our bioinformatics pipeline is designed for rigor, transparency, and biological relevance.
We leverage a robust computational infrastructure and an extensive suite of specialized software to handle the most demanding plant datasets.
Liquid Chromatography-Mass Spectrometry (LC-MS)

Gas Chromatography-Mass Spectrometry (GC-MS)

Nuclear Magnetic Resonance (NMR) Spectroscopy

We accept various data formats and biological inputs. To ensure high-quality analysis, please adhere to the following guidelines:
| Data/Sample Type | Minimum Requirements | Recommended Format/Condition |
| Biological Samples | Fresh tissue (frozen in liquid nitrogen) | 500 mg+ shipped on dry ice (for end-to-end service) |
| Raw Sequencing Data | >10 Gb for Transcriptomes; >100 Gb for Genomes | Raw FASTQ (compressed .gz) from Illumina, PacBio, or ONT |
| Processed Data | Read counts or FPKM/TPM matrices | csv, .txt, or .xlsx |
| Metabolomics Data | Peak tables and m/z intensity data | mzXML, .CDF, or standardized Excel sheets |
| Reference Information | Genome assembly and GFF/GTF annotation | FASTA/GFF3 (if provided by client) |

Plant-Centric Expertise
Unlike general providers, we understand plant-specific challenges like polyploidy and specialized cell walls.

Customizable Pipelines
We do not believe in "black box" analysis; every project is tailored to your specific biological question.

Publication-Ready Results
We provide high-resolution charts, detailed methodology sections, and raw data files.

Cross-Platform Integration
Expertise in integrating NGS, TGS (PacBio/Nanopore), and mass spectrometry data.
Unlock the hidden insights within your plant research data through our advanced bioinformatics expertise. Whether you require deep evolutionary tracing or complex multi-omics integration, our team provides the precision needed for your next discovery. Contact us today for a free technical consultation.
Plant bioinformatics analysis refers to the application of computational tools, algorithms, and statistical methods to analyze large-scale biological data generated from plant research. It enables researchers to efficiently process, integrate, and interpret complex datasets such as genomic, transcriptomic, proteomic, and metabolomic data.
By transforming raw sequencing or omics data into biologically meaningful insights, plant bioinformatics plays a critical role in understanding gene function, regulatory mechanisms, evolutionary relationships, and trait variation across plant species.
With the rapid development of high-throughput sequencing and omics technologies, plant research now generates massive volumes of data that cannot be analyzed using traditional experimental approaches alone. Bioinformatics provides the necessary framework to manage this complexity and extract actionable biological information.
Through advanced computational analysis, researchers can identify key genes, pathways, and molecular markers associated with agronomic traits, stress responses, and developmental processes, significantly accelerating plant science research and breeding programs.
Plant bioinformatics analysis enables systematic exploration of gene function and genetic variation at a genome-wide scale. By integrating sequence annotation, expression profiling, and comparative genomics, researchers can uncover candidate genes involved in specific biological processes or phenotypic traits.
In functional genomics and trait discovery studies, bioinformatics tools are widely used for differential expression analysis, gene family identification, pathway enrichment, and association analysis, providing critical insights that guide downstream experimental validation and crop improvement strategies.
Plant bioinformatics typically involves the analysis of multiple data types, including whole-genome sequencing data, RNA sequencing (RNA-seq), epigenomic data, and metabolomic profiles. These datasets can be analyzed individually or integrated to achieve a comprehensive understanding of plant biological systems.
Common analysis tasks include genome assembly and annotation, transcriptome profiling, variant detection, gene expression quantification, functional annotation, and network analysis, all of which contribute to a deeper understanding of plant structure, function, and adaptation.
Plant bioinformatics analysis is essential at various stages of plant research projects, from experimental design and data processing to result interpretation and hypothesis generation. It is particularly valuable when working with high-throughput datasets, complex traits, or comparative studies across species or varieties.
Whether the goal is to identify novel genes, analyze regulatory mechanisms, or support breeding and genetic transformation efforts, bioinformatics analysis provides a powerful foundation for data-driven decision-making and efficient research advancement.
We utilize subgenome-specific mapping strategies and specialized SNP-calling algorithms designed to differentiate between homeologs in allopolyploid species like wheat or cotton.
We provide de novo transcriptome or genome assembly services using long-read sequencing data (PacBio/ONT) to create a high-quality reference for your project.
Yes, our joint analysis pipelines are designed to integrate heterogeneous datasets, even if they were generated at different times, provided the experimental design is compatible.
All client data is stored on encrypted servers with strict access controls. We can sign Non-Disclosure Agreements (NDAs) to protect your intellectual property.
Absolutely. We provide detailed descriptions of all software, versions, and parameters used, along with the necessary citations for your manuscript.
Through our plant bioinformatics data visualization service, we provide heatmaps, circos plots, volcanic plots, and 3D protein models.

Detection of Arabidopsis SNP Genetic Markers

SSR Identification of Cotton Salt Tolerance

RAPD Analysis of Genetic Diversity for Salt Tolerance in Wheat

AFLP Analysis of Genetic Diversity and Genetic Relationships of Spinach Germplasm
 Download
DownloadEnter Your Details for Immediate PDF Access
Get Latest Lifeasible News and Updates Directly to Your Inbox
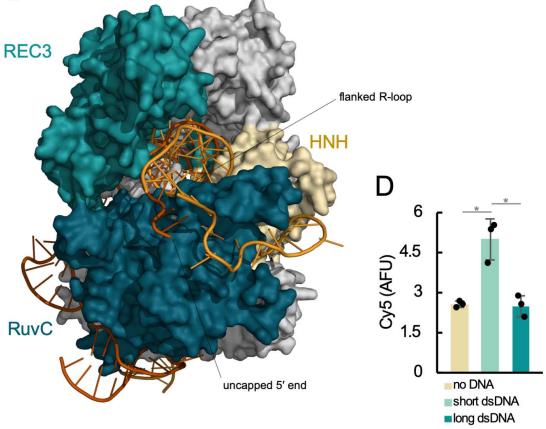
Structural Factors Affecting CRISPR-Cas9 Trans-Cleavage Activity
February 9, 2026
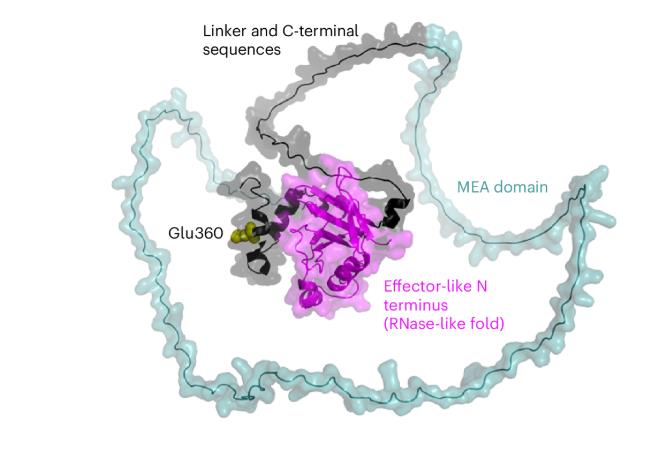
The Dual Identity of Wheat Powdery Mildew Effector Proteins
February 3, 2026